
Executive Summary
Beim Formulieren von Anforderungen im Zuge des Requirements Engineering ist Sprachkontrolle unerlässlich.
Anforderungen in natürlicher Sprache zu verfassen hat den Vorteil, dass keine Einarbeitung in eine spezielle Metasprache vonnöten ist. Außerdem genießen die Schreibenden eine verhältnismäßig große sprachliche Freiheit. Diese Freiheit hat jedoch auch den Nachteil, dass es mehr Spielraum für Fehler, Inkonsistenzen, Unklarheiten und weitere Textqualitätsprobleme gibt.
Unzureichende Textqualität kann im Requirements Engineering zu verschiedenen grundlegenden Problemen führen.
Um sich diesen Problemen zu stellen, greifen gängige Softwarelösungen zur Textqualitätssicherung im Requirements Engineering in der Regel auf wortbasierte Verfahren zurück. Vereinfacht gesagt bedeutet dies, dass zur Prüfung Wortlisten herangezogen werden, die z. B. so genannte „Weak-Words“, Unvollständigkeitsmarker und weitere lexikonbasiert abbildbare Muster abdecken.
Eine linguistisch intelligente maschinelle Autorenunterstützung vereint lexikonbasierte Verfahren mit einem tiefer greifenden Analyseverfahren, einer morpho-syntaktischen Analyse. Wörter und Sätze werden in ihre kleinsten bedeutungstragenden Bestandteile zerlegt und analysiert. Damit können auch komplexe Problematiken wie fehlende Wortbezüge, falsche Wortstellung oder stilistische Unzulänglichkeiten erkannt werden. Zudem ist eine linguistisch intelligente maschinelle Autorenunterstützung dazu in der Lage, Dokumentstruktur-abhängig zu prüfen, also spezialisierte Prüfregeln auf bestimmte Textformate anzuwenden.
Der Umstand, dass entsprechende Software zur Autorenunterstützung regelbasiert funktioniert, bringt einen weiteren großen Vorteil mit sich: Es kann auf ein sehr umfangreiches und bewährtes Regelrepertoire zugegriffen werden. Es können sowohl individuelle Regelkonfigurationen zusammengestellt als auch neue Regeln implementiert werden. So kann die Autorenunterstützung allgemeine Textqualitätskriterien im Requirements Engineering prüfbar machen und gleichzeitig, wenn gewünscht, sprachliche Unternehmensspezifika abdecken. Zu diesen zählt auch die jeweilige Unternehmensterminologie. Linguistisch basierte Analyseverfahren erstrecken sich im Kontext moderner Software zur Autorenunterstützung auch auf diesen Bereich: Die konsistente Einhaltung der Unternehmensterminologie wird durch die Software gewährleistet.
Satzwiederverwendung ist ein Thema, das von gängigen Softwarelösungen zur Textqualitätssicherung im Requirements Engineering weitestgehend nicht behandelt wird. Dabei bietet Satzwiederverwendung weit reichende Vorteile. Wenn bereits sprachlich geschliffene Anforderungen existieren, können diese in einem Satzspeicher abgelegt und jederzeit wiederverwendet werden. Bestenfalls sind dann keine bis wenige Anpassungen am übernommenen Satz notwendig. Die Autorinnen und Autoren sparen Zeit (und damit Geld), weil sie nicht alles neu schreiben müssen, und die Textqualität der übernommenen Anforderung ist bereits in der Vergangenheit gesichert worden. Ebenfalls hilft Satzwiederverwendung dabei, Konsistenz auf Formulierungsebene zu bewahren, was den Lesefluss und damit letztendlich die Verständlichkeit und Eindeutigkeit der Anforderungen positiv beeinflusst. Und dies kommt allen Beteiligten im Prozess des Requirements Engineering zugute.
Zusammenfassend: Mit einer modernen maschinellen Autorenunterstützung wie dem Congree Authoring Server stellen Sie die sprachliche Qualität Ihrer Anforderungen im Requirements Engineering sicher. Durch den Einsatz linguistisch intelligenter Verfahren lassen sich im Gegensatz zu anderen Softwarelösungen vergleichsweise komplexe Textqualitätsproblematiken erkennen und beheben. Zudem wird Konsistenz sichergestellt, vor allem durch die Einhaltung der Unternehmensterminologie.
Einführung
Requirements Engineering, frei übersetzt Anforderungsmanagement, bezeichnet den Umgang, vor allem das Erstellen und Verwalten von Anforderungen im Entwicklungsprozess, z. B. von Software. Dabei kommt Anforderungen eine wichtige und vielschichtige Rolle zu. Zwei grundlegende Fragestellungen, die Requirements Engineering sinnvoll erscheinen lassen, sind:
- Was sind die Erwartungen rund um das Produkt? Was erwarten Auftraggeber, Endbenutzer, Kapitalgeber und weitere Stakeholder?
- Was muss von den Entwicklern wie umgesetzt werden?
Zudem sind vollständige, korrekte und passend dokumentierte Anforderungen wichtig, um bei einer späteren Produktweiterentwicklung an ihnen ansetzen zu können (Quelle).
In diesem Dokument wird dargestellt, warum Textqualität ein wesentlicher Faktor ist, um sinnvolles Requirements Engineering zu betreiben. Darauf aufbauend wird gezeigt, wie mit linguistisch intelligenter maschineller Autorenunterstützung sprachliche Stolpersteine umgangen werden können, um die Textqualität sicherzustellen.
Requirements Engineering: sprachliche Merkmale
Grundsätzliches
Mitunter werden Anforderungen in formalen Sprachen wie UML (Unified Modelling Language) verfasst, die zur Beschreibung von Systemen konzipiert wurden. Meistens wird für Anforderungen, die im Zuge des Requirements Engineering formuliert werden, natürliche Sprache genutzt. Diese muss nicht erst erlernt werden, was es einfacher macht, in das Formulieren von Anforderungen einzusteigen (Quelle). Dass natürliche Sprache nicht erst erlernt werden muss, ist nicht nur für die Schreibenden, sondern auch für sämtliche Stakeholder vorteilhaft. Sie können die Anforderungen lesen und verstehen, ohne neue Notationen oder Sprachen zu lernen. In Hinblick auf bestimmte Notationen respektive formale Sprachen, die sich mitunter nur auf bestimmte Anforderungsgebiete beziehen – z. B. auf Software –, hat natürliche Sprache noch einen weiteren Vorteil: Sie ist universell und kann für alle Arten von Anforderungen verwendet werden (Quelle: Reuther, Ursula und Koch, Matthias (o. J.): Automatisierte Qualitätssicherung von Anforderungen mit Hilfe linguistischer Regeln).
Natürliche Sprache tritt im Requirements Engineering meist entweder als Freitext oder im Kontext von strukturierten Vorlagen auf (Quelle: ebd.).
Sprachliche Herausforderungen

Natürliche Sprache bietet den Schreibenden gegenüber formalen Sprachen einen hohen Grad an Formulierungsfreiheit. Die Herausforderung: Je mehr Freiheit, desto mehr Inhaltsvarianten entstehen, weil jeder Mensch einen eigenen Schreibstil und individuelle Stärken und Schwächen hat. Dies bietet einen vergleichsweise größeren Spielraum für Fehler oder unnötige Varianten.
Eines der zentralen Qualitätsprobleme von Präzision und Eindeutigkeit ist (fach-) lexikografischer Natur: Weak-Words, auch unscharfe Wörter genannt, verstoßen in gewissen Kontexten gegen die aufgeführten Qualitätskriterien. Weak-Words sind „Wörter oder Phrasen, deren Benutzung in einem Freitext darauf schließen lässt, dass der Freitext mit hoher Wahrscheinlichkeit unpräzise ist“ (Quelle).
Welche Probleme in der Praxis primär auftreten, wurde 2003 von Kandt untersucht: Dabei wurden 967 natürlichsprachliche Anforderungen betrachtet. Davon wiesen ganze 223 Anforderungen, also fast ein Viertel der Gesamtanzahl, die bereits thematisierten Weak-Words auf. Die zweithäufigste Problemstelle bezog sich auf Grammatik: 83 Anforderungen waren fälschlicherweise nicht im Singular formuliert. Des Weiteren wurden stilistische Probleme ermittelt: 53 Anforderungen waren nicht kurz und einfach, 37 Anforderungen waren unvollständig und 23 Anforderungen verwendeten Negierungen (Quelle: Kandt, R. K. 2003: Software Requirements Engineering: Practices and Techniques. JPL Document D-24994. SQI Report R-3. Jet Propulsion Laboratory. California Institute of Technology).
Die besonders häufig auftretenden sprachlichen Fehler bzw. Probleme erstrecken sich über fast alle Kategorien. Hier muss eine etwaige Textqualitätssicherung, ob manuell oder softwarebasiert, ein breites sprachliches Spektrum abdecken.
Warum Textqualität im Requirements Engineering so wichtig ist
Um diese Frage zu beantworten, soll zuerst ein Blick auf die Nachteile geworfen werden, die entstehen, wenn Anforderungen gar nicht erst dokumentiert werden. Dieser Extremfall führt dazu, dass
- die Softwareentwicklung nicht weiß, was genau zu tun ist.
- Kunden – im Zuge von Paid Development – den Umfang des von ihnen bezahlten Produkts nicht vor der Fertigstellung überblicken können.
- nicht klar definiert ist, wann ein Produkt „fertig“ ist.
- Qualitätsprüfer keine Richtlinien haben, anhand derer sie das fertige Produkt testen können (Quelle).
Schlecht geschriebene Anforderungen sind besser als gar keine dokumentierten Anforderungen. Dennoch können Textqualitätsmängel im Extremfall auch zu den geschilderten Problemen führen. Schlimmstenfalls kann es zur Rückforderung von Geld kommen, wenn das fertige Produkt nicht mit den Vorstellungen der Kunden übereinstimmt. Hier kann mit klaren, verständlichen Anforderungen viel Geld eingespart werden.
Maßstäbe für Textqualität im Requirements Engineering
Um die Frage zu beantworten, wie Anforderungen im Requirements Engineering formuliert werden sollen, existiert neben der Norm ISO/IEC/IEEE 29148 außerdem der Leitsatz „Completeness – Consistency – Correctness“ (Quelle). Alspaugh et al. nennen zudem noch „Clarity“, also Klarheit, als wichtige sprachliche Eigenschaft von Anforderungen (Quelle: Alspaugh, T.A., Elliott, S., Winbladh, S.K., Diallo, M.H., Naslavsky, L., Ziv, H., & Richardson, D. (2006). The Importance of Clarity in Usable Requirements Specification Formats).
Doch wie lassen sich diese Eigenschaften sprachlich realisieren? Dem soll in den folgenden Abschnitten nachgegangen werden.
Correctness: Rechtschreibung und Grammatik
Korrektheit ist eine grundlegende Texteigenschaft. Sie ist auf der inhaltlichen, aber auch auf der formalen Ebene von Sprache zu finden. An dieser Stelle soll das „wie“ thematisiert werden, und damit die formale Ebene. Bei textueller Korrektheit geht es nicht um stilistische Merkmale, sondern darum, ob Texte gemessen an sprachlichen Vorgaben fehlerfrei sind. Diese Vorgaben finden sich in Rechtschreib- und Grammatikregelungen – eine besonders weite Verbreitung und Akzeptanz kommt im Deutschen z. B. den Duden-Publikationen zu.
Clarity: Verbindlichkeit, Eindeutigkeit, Verständlichkeit
Klarheit ist eine Texteigenschaft, die sich nicht so deutlich umreißen lässt wie Korrektheit. Man kann hier die Parameter Verbindlichkeit, Eindeutigkeit und Verständlichkeit nennen, die zusammen die Eigenschaft „Klarheit“ näher definieren. Was diese Eigenschaften textuell ausmacht, soll nun näher beschrieben werden. Dazu ist anzumerken, dass für jede der drei Eigenschaften neben den genannten Merkmalen noch weitere Merkmale existieren, auf die nicht im Einzelnen eingegangen wird.
Verbindlichkeit
Verbindlichkeit durch Sprache auszudrücken, bedeutet vor allem den Verzicht auf vage Ausdrucksweisen. Dazu zählen:
- „man“: Das Indefinitpronomen „man“ drückt das Subjekt eines Satzes aus, ohne eine konkrete Person zu benennen. In der Praxis kann dies z. B. dazu führen, dass eine Aussage eine Anweisung mit „man“ enthält, aber niemand sich verantwortlich fühlt, die Anweisung auszuführen, da niemand explizit angesprochen wurde. Weiterhin ist es denkbar, dass Stakeholdern durch den Gebrauch von „man“ nicht klar wird, welchen Personen im Entwicklungsprozess welche Rolle zukommt. Hier kann es in der Folge leicht zu Missverständnissen kommen.
- Konjunktiv II: Mitunter zusammen mit „man“, aber oft auch mit konkretem Subjekt, tritt der Konjunktiv II auf. Konstruktionen wie „Jana würde die Software nutzen“ bleiben vage. Es wird keine klare Aussage getroffen, ob Jana die Software wirklich nutzt oder nicht.
- Modalverben: Ebenso wie der Konjunktiv können auch Modalverben die Verbindlichkeit einer Aussage schmälern. Sie fügen dem Hauptverb eine gewisse Unsicherheit hinzu. „Das System kann abstürzen, wenn XY passiert“ sagt nichts darüber aus, was wirklich passiert, wenn Fall XY eintritt. Im Requirements Engineering ist hingegen wichtig, dass Fakten möglichst präzise und nicht nur als Möglichkeit beschrieben werden.
- „beziehungsweise“ und „bzw.“: Auch „beziehungsweise“ und seine Abkürzung „bzw.“ sind in passend geschriebenen Anforderungen nicht angebracht. Warum? „Beziehungsweise“ hat zwei Bedeutungen: „Genauer gesagt“ und „im anderen Fall“ (Quelle). In Sätzen mit dem Muster „[Aussage 1] beziehungsweise [Aussage 2]“ bedeutet das, dass entweder Aussage 2 Aussage 1 konkretisiert oder Aussage 2 Aussage 1 einen „Gegenfall“ hinzufügt.
Wenn eine Aussage eine Konkretisierung benötigt, ist anzunehmen, dass sie nicht verbindlich und aussagekräftig genug formuliert wurde. Das kann die inhaltliche Aufnahme der Anforderung empfindlich stören. Und einen Gegenfall innerhalb eines Satzes zu formulieren, ist wenig übersichtlich und nicht eindeutig. Zwei separate Aussagen sind besser zu erfassen. Zudem wirkt – und hier kommt wieder die Verbindlichkeit ins Spiel – eine Aussage schnell unverbindlich, wenn im selben Satz bereits eine Gegenaussage getätigt wird. - Weichmacher: Um zu illustrieren, wie Verbindlichkeit durch Weichmacher reduziert wird, stellt „vielleicht“ ein gutes Beispiel dar. Wenn innerhalb einer Anforderung die Aussage getätigt wird, dass Aktion A im System die Reaktion B hervorruft, ist dem Entwicklungsteam klar, wie es das Systemverhalten gestalten muss. Die Aussage, dass Aktion A vielleicht die Reaktion B hervorruft, ist hingegen gänzlich unverbindlich und damit unbrauchbar.
Eindeutigkeit
Um Eindeutigkeit zu erzielen, müssen Ambiguitäten vermieden werden. Um Ambiguitäten zu vermeiden, lohnt es sich, bei den folgenden sprachlichen Entitäten genauer hinzusehen:
- Passiv-Konstruktionen: Passiv-Konstruktionen sind häufig problematisch, da sie den Fokus auf eine Handlung rücken, dafür aber das Agens auslassen. Je nach Textsorte kann das sinnvoll sein, im Rahmen des Requirements Engineerings jedoch in der Regel nicht. Eine Anforderung ist maximal eindeutig, wenn das Agens benannt wird.
- Pronominale Wiederaufnahme ist an für sich nichts Schlechtes. Allerdings kann sie in bestimmten Fällen dazu führen, dass Ambiguitäten entstehen.
Unproblematisch ist z. B. „Der Ball war rund. Er lag auf dem Tisch.“ Der erste Satz enthält nur ein Substantiv und der zweite Satz nur ein Pronomen. Dieses passt grammatisch und lässt sofort darauf schließen, dass „er“ das Substantiv „Ball“ wieder aufnimmt.
In diesem umgangssprachlichen Beispiel wird es hingegen problematisch: „Julius legte den Ball auf den Tisch. Er war ganz schön platt.“ Es ist nicht eindeutig bestimmbar, ob „er“ sich auf den Ball oder Julius bezieht. Eine Ambiguität ist entstanden. Daher gilt es, entsprechende Konstruktionen zu entschärfen, indem z. B. das Substantiv wiederholt wird, anstatt es mit einem Pronomen wiederaufzunehmen. - Subjekt-Objekt-Stellung: Die Stellung von Subjekt und Objekt spielt eine wichtige Rolle beim Vermeiden von Ambiguitäten. Für gewöhnlich steht das Subjekt im Satz vor dem Objekt. Es ist im Deutschen allerdings zulässig, wenn auch unkonventionell, das Objekt vor dem Subjekt zu nennen. Dennoch kann diese umgekehrte Stellung zu Ambiguitäten führen. Wer einen Satz liest, erwartet unbewusst die Subjekt-Objekt-Stellung und interpretiert den Satz daher womöglich aufgrund seiner Erwartungshaltung falsch. Während die Objekt-Subjekt-Stellung z. B. im Journalismus Texte aufzupeppen vermag, sollte im Requirements Engineering der Fokus auf Eindeutigkeit gelegt werden. Die Subjekt-Objekt-Stellung gilt es daher einzuhalten.
Verständlichkeit
Textverständlichkeit hängt von vielen verschiedenen Faktoren ab. Auf einem guten Weg zu verständlichen Texten sind Sie, wenn Sie folgende Konstruktionen vermeiden oder einschränken:
- Präpositionalphrasen: Präpositionalphrasen sind für sich genommen kein Problem – problematisch werden sie erst dann, wenn zu viele von Ihnen in einem Satz auftreten. Ab einer gewissen Anzahl sind die Bezüge der Präpositionalphrasen zueinander schwerer zu identifizieren. Ein extremes Beispiel hierfür ist „Undichtheit am Kraftstoff-Entlüftungswellrohr von rechter Tankkammer zu Tankeinfüllstutzen infolge Knickbeschädigung anlässlich der Tankmontage.“ Wie viele Präpositionalphrasen zu viel sind, kann nicht allgemein gültig festgelegt werden. Vier pro Satz können z. B. die Schwelle darstellen, wo diese aber im Einzelfall liegt, muss individuell pro Unternehmen oder Abteilung bestimmt werden.
- Viele Bedeutungseinheiten in einem Satz bewirken eine höhere Informationsdichte. Wenn die Informationsdichte sehr groß ist, leidet das Textverständnis – vereinfacht gesagt muss das Gehirn auf zu kleinem Raum zu viel Input aufnehmen. Die Grenze zwischen vielen und zu vielen Bedeutungseinheiten muss, ebenso wie bei den Präpositionalphrasen, individuell festgelegt werden.
- Lange Sätze sind nicht unbedingt förderlich für die Textverständlichkeit. Je länger der Satz, desto größer der Gefahr, dass Lesende am Satzende schon nicht mehr genau wissen, wie der Satz begonnen hat. Der Satz muss womöglich mehrmals gelesen werden und insgesamt ist die Informationsentnahme erschwert. Es gilt – eigentlich überall und besonders im Requirements Engineering –, Sätze möglichst kurz zu halten. 20-26 Wörter als Maximallänge könnten einen Richtwert darstellen, jedoch sollten hier auch unternehmensspezifische oder fachgebietsspezifische Vorgaben bedacht werden.
- Das Verbteil-Problem: Ein Merkmal der deutschen Sprache ist das Vorkommen von Verbklammern. Ein Beispiel: „Mit dem Produkt kann der Schalter, der für das Licht zuständig ist, ohne Probleme an die Wand angebracht werden.“ Zwischen den Verbteilen „kann“ und „angebracht werden“ stehen hier 13 Wörter. Je mehr Wörter die Verbklammer-Teile voneinander trennen, desto weniger verständlich der Satz. Diese Herausforderung ist häufig in sehr langen Sätzen anzutreffen. Um Verständlichkeit zu wahren, gilt es, die Verbteile so nah beieinander zu halten, wie möglich.
Consistency: Terminologie und Wiederverwendung
Konsistenz (Consistency) ist ein Komplex, der sich gleich auf mehreren sprachlichen Ebenen ansiedelt. Zum einen gibt es die stilistische Konsistenz: ein gleich bleibender Stil über Satz-, Text-, womöglich sogar Abteilungsgrenzen hinaus. Die Vorgabe, gleiche Sachverhalte sprachlich immer gleich darzustellen, ist dafür ein Beispiel. Diese Vorgabe stellt einen wichtigen sprachlichen Erfolgsfaktor in der Welt des Requirements Engineering dar. Im Fokus dieses Kapitels sollen allerdings die terminologische Konsistenz und die Konsistenzwahrung mittels Wiederverwendung stehen.
Terminologische Konsistenz
Die korrekte und konsistente Verwendung von Terminologie bietet zahlreiche Vorteile für Unternehmen. Auch im Requirements Engineering bringt eine konsistent verwendete Terminologie viele Vorteile mit sich. Aus diesem Grund ist es wünschenswert, der Anforderungsspezifizierung ein Glossar beizulegen, das einen Überblick über den relevanten Fachwortschatz im Dokument verschafft.
Wenn die Anforderungen konsistent die im Glossar festgelegten Benennungen enthalten, sind die positiven Folgen (Quelle):
- Stakeholder, die den Fachwortschatz noch nicht kennen, können sich damit vertraut machen.
- Es wird sichergestellt, dass alle Stakeholder „dieselbe Sprache sprechen“. Das vermeidet Missverständnisse und potenzielle Ambiguitäten.
Beim Formulieren von Anforderungen kann es eine Herausforderung darstellen, den Fachwortschatz konsistent anzuwenden und keine terminologischen Varianten zu erzeugen. Dem Bewältigen dieser Herausforderung sollte eine hohe Priorität zugemessen werden, denn inkonsistente Terminologie in Anforderungen macht nicht nur die geschilderten Vorteile zunichte. Sie sorgt darüber hinaus auch noch dafür, dass Inhalte der Anforderungsspezifikation schlechter oder gar nicht auffindbar sind. Das geschieht, weil die Inhalte nicht der definierten Terminologie entsprechen, die den Stakeholdern als Suchhilfe und Orientierung dient.
Konsistenz durch Wiederverwendung
Das Gegenteil von Konsistenz ist, vereinfacht gesagt, die Variantenvielfalt. Das gilt für Terminologie, aber auch für ganze Sätze oder gar Module. In Unternehmen entsteht mit der Zeit mehr und mehr Content, auch das Requirements Engineering bildet hier keine Ausnahme. Dabei ist es unwahrscheinlich, dass jeder neue Satz eine neue Idee illustriert. Häufig sind neue Inhalte in ähnlicher Form schon einmal „da gewesen“. Wenn frei formuliert wird, ist es jedoch naheliegend, dass der neu entstehende Satz sprachlich anders gestaltet wird als der bereits vorliegende. Im Satzrepertoire des Unternehmens existieren somit zwei sprachliche Varianten eines Inhalts.
Diese Satzvarianten gilt es zu vermeiden. Wenn Sätze, die allen sprachlichen Qualitätsrichtlinien entsprechen, gespeichert und beim Verfassen von Anforderungen zur Wiederverwendung angeboten werden, entstehen zahlreiche Vorteile. Die Schreibzeit wird durch das Übernehmen von Texten verkürzt. Stakeholder, die bereits mit ähnlichen Anforderungsdokumenten gearbeitet haben, treffen gewohnte und einmal verstandene Sätze wieder an. Wenn innerhalb eines Dokuments auf existierende, bewährte Formulierungen zurückgegriffen wird, erhöht dies die Textverständlichkeit.
Completeness: Satzschablonen
Vollständigkeit wird im Requirements Engineering in der Regel als inhaltliches Kriterium verstanden. In sprachlicher Hinsicht ist die syntaktische, also die strukturelle Vollständigkeit auf Satzebene zu nennen. Erst vollständige Sätze ergeben korrekte Anforderungen.
Formalisiert werden kann syntaktische Vollständigkeit z. B. mit Satzschablonen.
Gängige Methoden zur Textqualitätssicherung im Requirements Engineering
Um den textuellen Herausforderungen zu begegnen, die natürlichsprachliche Anforderungen im Requirements Engineering mit sich bringen, gibt es bereits verbreitete Methoden. Sie lassen sich grob in zwei Gebiete unterteilen:
- Einschränkung des sprachlichen Inventars
- Wortlisten- und musterbasiertes Suchen nach unerwünschten Konstruktionen
Diese sollen in den folgenden Abschnitten erläutert werden.
Einschränkung des sprachlichen Inventars
Textsorten wie Lyrik und Prosa schöpfen aus der Vielzahl von Worten und Stilarten einer Sprache. Im Requirements Engineering gilt das Gegenteil: Texte sollen nicht „schön“, sondern funktional sein. Korrekt, konsistent und vollständig. Ein Weg, um dies zu erreichen, ist das Anwenden einer so genannten „Requirements Syntax“. Das folgende Zitat erläutert das Prinzip einer “Requirements Syntax”:
Das Zitat bezieht sich zwar auf den bekannten „EARS“-Ansatz, illustriert aber treffend, worum es bei einer „Requirements Syntax“ geht.
Feste, regelbasierte Struktur, erlaubte Wörter – es besteht hier eine gewisse Ähnlichkeit zu präskriptiven Kontrollierten Sprachen.
Kontrollierte Sprachen nach dem präskriptiven Ansatz schreiben „erlaubte“ Begriffe und Strukturen vor, während beim so genannten proskriptiven Ansatz „nicht erlaubte“ sprachliche Entitäten festgelegt werden. Beide Ansätze bringen Vor- und Nachteile mit sich. Für den präskriptiven Ansatz spricht, dass durch die Vorgabe von erlaubten Strukturen im Vergleich zum proskriptiven Ansatz weniger Formulierungsfreiheit gegeben ist. Dies kann sich durchaus positiv auf die Textkonsistenz auswirken, unter anderem auch, wenn mehrere Autoren beteiligt sind. Die eingeschränkte Formulierungsfreiheit könnte jedoch auch als Nachteil aus der Sicht der Autoren gewertet werden, woraus Akzeptanzprobleme erwachsen könnten. Außerdem kann vermutet werden, dass aus der größeren Anzahl zu lernender Regeln ein vergleichsweise höherer Schulungsbedarf für den präskriptiven Ansatz resultiert. Vorteile des proskriptiven Ansatzes sind, dass er den technisch Schreibenden größere Formulierungsfreiheit lässt. Außerdem führt der proskriptive Ansatz dazu, dass die Fehlermeldungen durch Prüfprogramme vergleichsweise spezifischer gestaltet sind – schließlich benennen diese konkret die Verstöße der Autoren. Nachteil des proskriptiven Ansatzes ist, dass bei vielen „nicht-falschen“ Möglichkeiten, einen Text zu gestalten, mehr Raum für inkonsistente Gestaltung bleibt. Vereinfacht gesagt sind die Schwächen eines Standards die Stärken des anderen.
Wortlisten- und musterbasiertes Suchen nach unerwünschten Konstruktionen
Neben der Möglichkeit, eine „Requirements Syntax“ anzuwenden, existieren weitere Methoden, um die Textqualität im Requirements Engineering zu sichern. Diese lassen sich dem proskriptiven Ansatz zuordnen und werden häufig auf Basis von Wortlisten realisiert. Konkret geht es um das Erkennen und Monieren folgender unerwünschter Konstruktionen in Anforderungen:
- Weak-Words
- Multiplizität
- Negationen
- Unvollständigkeit (z. B. von den Schreibenden durch „TBC“ oder „TBD“ markiert)
- Passiv
- Subjektive Formulierungen
- Optionalität
- Implizität
- Uneindeutigkeit
- Vergleichende Phrasen (Quelle: Reuther, Ursula und Koch, Matthias (o. J.): Automatisierte Qualitätssicherung von Anforderungen mit Hilfe linguistischer Regeln)
Die geschilderten Methoden erkennen eine ganze Menge kritischer sprachlicher Konstruktionen im Rahmen des Requirements Engineering und helfen beim Formulieren angemessener Texte.
Doch auch sie haben Schwächen. Beim Thema „Requirements Syntax“ sei der Schulungsbedarf an erster Stelle zu nennen. Aber auch die Tatsache, dass immer noch Lücken in der Syntax bestehen, die Schreibende selbst befüllen müssen, eröffnet einen gewissen Spielraum für Fehler.
Fehler erkennen – dies ist grundlegend für den proskriptiven Ansatz. Obwohl die gängigen, wortlistenbasierten Verfahren viele Problematiken erkennen und monieren, entgehen ihnen tief greifende textuelle Probleme, die auf Basis von Wortlisten nicht prüfbar sind.
Dazu kommt: Reine Wortlistensuchen geschehen kontextunabhängig. So werden viele potenzielle Fehler gefunden, aber auch viele unnötige Warnungen generiert, denn Textqualitätsprobleme sind in der Regel in unterschiedlichen Textstrukturen (Überschriften, Listen, Fließtext etc.) unterschiedlich relevant. Das Problem der Kontextunabhängigkeit besteht auch, wenn Wortlistensuchen um musterbasierte Suchmethoden, z. B. auf Basis regulärer Ausdrücke, erweitert werden.
Die Performanz ist bei musterbasierten Suchmethoden höher als bei der Wortlistenmethode. Allerdings können sprachlich komplexe Problematiken wie z. B. Flexions- oder Termvarianten hiermit nicht oder nur unzureichend abgedeckt werden. Ebenso kann eine rein stringbasierte Suche keine syntaktischen Abhängigkeiten erkennen. Beispielsweise kann „nicht mehr als“ als „Weak-Word“ in einen Satz wie „Der Wert darf nicht mehr als 7 betragen.“ auftreten. Eine stringbasierte Regel, die diese Konstruktion moniert, schlägt allerdings auch bei korrekten Sätzen wie „Der Wert erscheint nicht mehr als Pfeil, sondern als pulsierendes Signal.“ zu.
Moderne Autorenunterstützung im Requirements Engineering
Unterschiede zu traditionellen Ansätzen
Gängiger Software für die Textqualitätssicherung im Requirements Engineering liegt in den meisten Fällen ein proskriptiver Ansatz zu Grunde: Sie prüft auf Basis von formalen Regeln nach nicht erlaubten Konstruktionen. Dabei können Wortlisten und musterbasierte Suche zum Einsatz kommen.
Software wie der Congree Authoring Server geht noch einen Schritt weiter. Sie verfügt über eine Sprachprüfung auf Basis linguistischer Algorithmen. Das bedeutet, dass die Linguistic Engine der Software die zu analysierenden Texte in ihre kleinsten bedeutungstragenden Elemente, die Morpheme, zerlegt und durch die syntaktische Analyse die Satzstruktur erkennt. So können selbst komplexe Grammatikfehler, Stilfehler oder komplexe Varianten von nicht erlaubten Benennungen erkannt werden.
- Rechtschreibung und Grammatik allgemein
- Erkannt von traditionellen Ansätzen: eingeschränkt
- Erkannt von Congree: ja
- „man“
- Erkannt von traditionellen Ansätzen: ja
- Erkannt von Congree: ja
- Konjunktiv II
- Erkannt von traditionellen Ansätzen: eingeschränkt
- Erkannt von Congree: ja
- Modalverben
- Erkannt von traditionellen Ansätzen: eingeschränkt
- Erkannt von Congree: ja
- „beziehungsweise“/„bzw.“
- Erkannt von traditionellen Ansätzen: ja
- Erkannt von Congree: ja
- Weichmacher
- Erkannt von traditionellen Ansätzen: ja
- Erkannt von Congree: ja
- Passiv
- Erkannt von traditionellen Ansätzen: eingeschränkt
- Erkannt von Congree: ja
- Pronominale Wiederaufnahme
- Erkannt von traditionellen Ansätzen: nein
- Erkannt von Congree: ja
- Subjekt-Objekt-Stellung
- Erkannt von traditionellen Ansätzen: nein
- Erkannt von Congree: ja
- Zu viele Präpositionalphrasen
- Erkannt von traditionellen Ansätzen: ja
- Erkannt von Congree: ja
- Zu viele Bedeutungseinheiten
- Erkannt von traditionellen Ansätzen: nein
- Erkannt von Congree: ja
- Lange Sätze
- Erkannt von traditionellen Ansätzen: ja
- Erkannt von Congree: ja
- Verbteile zu weit auseinander
- Erkannt von traditionellen Ansätzen: nein
- Erkannt von Congree: ja
- Terminologie
- Erkannt von traditionellen Ansätzen: ja
- Erkannt von Congree: ja, inklusive Varianten
- Satzwiederverwendung
- Erkannt von traditionellen Ansätzen: nein
- Erkannt von Congree: ja
- Satzschablonen
- Erkannt von traditionellen Ansätzen: ja
- Erkannt von Congree: nein
Die tiefere, komplexere sprachliche Analyse stellt den hauptsächlichen Unterschied zwischen moderner, linguistisch basierter Software zur Autorenunterstützung und traditionellen Textqualitätssicherungstools für das Requirements Engineering dar. Ein weiteres Unterscheidungsmerkmal ist die kontextabhängige Prüfung: Software wie der Congree Authoring Server wendet seine Prüfregeln abhängig von der Dokumentstruktur an. Je nach Konfiguration gelten für Titel, Absatz oder Listen unterschiedliche, jeweils passende Regeln. Das Risiko von Fehlalarmen (false positives) wird minimiert.
Umsetzbarkeit
Es existieren bereits zahlreiche Regeln, die im Kontext Technischer Dokumentation jahrelang erfolgreich Anwendung finden. Diese Regeln entsprechen überwiegend auch jenen, die im Requirements Engineering gefragt sind (Quelle: Reuther, Ursula und Koch, Matthias (o. J.): Automatisierte Qualitätssicherung von Anforderungen mit Hilfe linguistischer Regeln). Das Regelrepertoire ist daneben auch erweiterbar, sodass unternehmensspezifisch entstehender Regelbedarf abgedeckt werden kann.
Bei der Frage nach der Umsetzbarkeit schwingt stets auch die konkrete technische Realisierung mit. Software zur Sprachkontrolle muss dort eingesetzt werden, wo Text entsteht. Daher bietet entsprechende Software in der Regel auch vielfältige Integrationsmöglichkeiten. Im Rahmen des Congree Authoring Servers als Beispiel für moderne, linguistisch basierte Software zur Autorenunterstützung bedeutet das: Es gibt gleich mehrere grundsätzliche Wege der Integration:
Vollintegration
Die Software kann als Plug-In für eine Vielzahl von Desktop-Applikationen installiert werden. Ein Beispiel stellen die Microsoft-Office-Applikationen dar, deren Vertreter Microsoft Word häufig als Editor für Anforderungsdokumente genutzt wird.

Browser-Plug-in
Wenn Anwendungen zur Erstellung oder Bearbeitung von Anforderungsdokumenten in einem Internetbrowser genutzt werden, kommt das Congree-Browser-Plug-In zum Einsatz. Es ermöglicht den Einsatz der Sprachprüfung überall dort, wo online Text entsteht, z. B. in Atlassian JIRA:
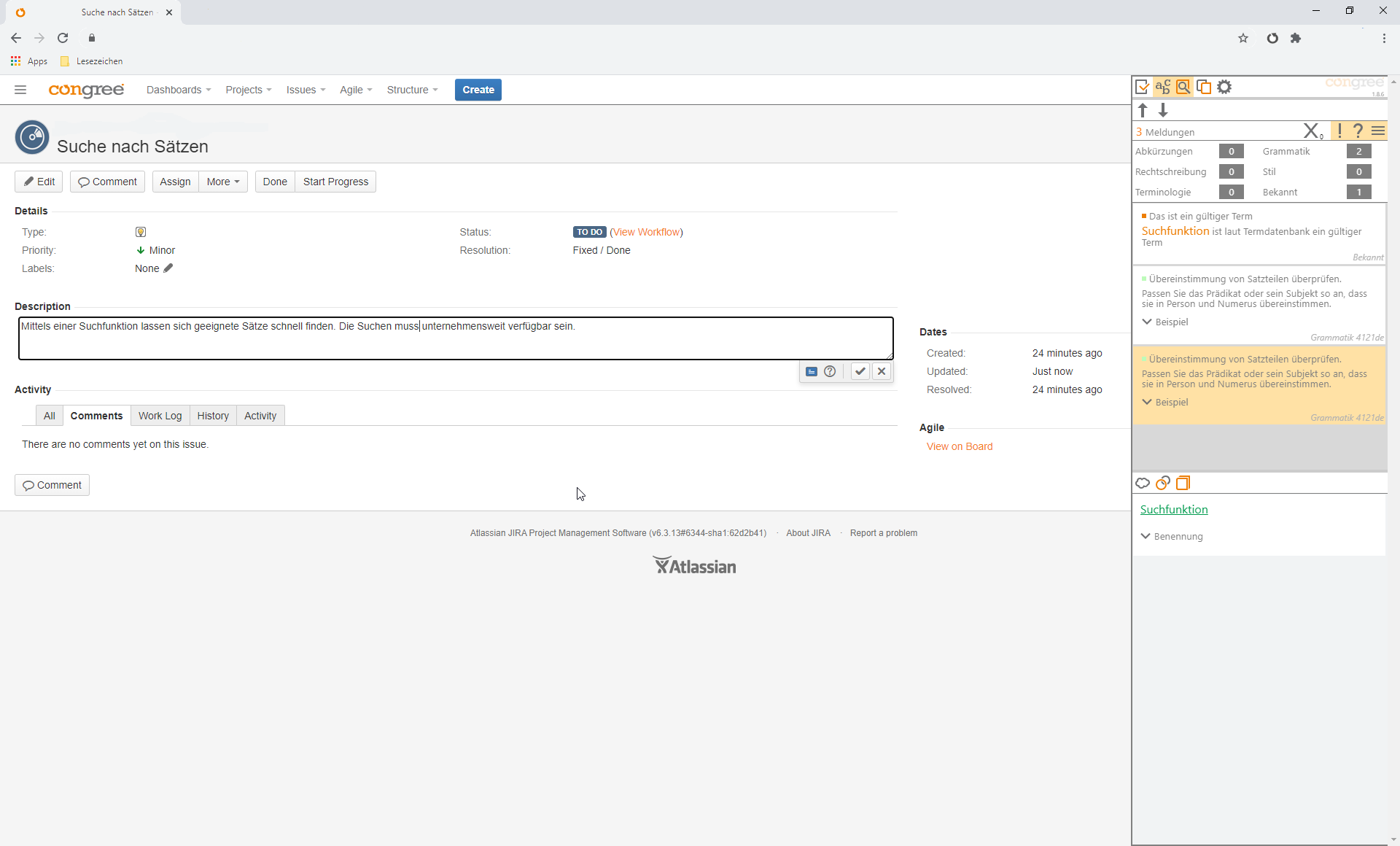
APIs
Wenn im Requirements Engineering eine Softwarelösung zum Einsatz kommt, für die keine Vollintegration existiert, lässt sich die Autorenunterstützung dennoch einfach integrieren – in diesem Fall auf Basis von APIs.
Fazit
Requirements Engineering findet statt, wenn Anforderungen an ein System, ein Produkt formuliert werden. Dies geschieht zumeist in natürlicher Sprache. Durch die Tatsache, dass an jedem Projekt verschiedene Stakeholder mit verschiedenen Interessen, Kenntnisständen und Blickwinkeln beteiligt sind, spielt Verständlichkeit eine zentrale Rolle. Doch auch andere Kriterien wie Korrektheit, Eindeutigkeit, Verbindlichkeit und terminologische wie stilistische Konsistenz sind sprachlich relevant für das Formulieren guter, zielführender Anforderungen im Zuge einer Anforderungsdokumentation.
Es existieren zahlreiche traditionelle Ansätze und Tools, die viele sprachliche Problemgebiete des Requirement Engineerings abdecken. Es gibt allerdings zahlreiche Abdeckungslücken, die primär methodisch bedingt sind – entsprechende Tools bedienen sich wortlisten- und musterbasierter Analysemethoden. Diese Abdeckungslücken werden von moderner linguistisch basierter Software zur Autorenunterstützung geschlossen. Durch das Zerlegen von sprachlichen Inhalten in Morpheme können Sätze tief greifend analysiert werden. Das geschieht abhängig vom Satzkontext, sodass unnötige Fehlalarme der Prüfung minimiert werden können. Als Beispiel für entsprechende linguistisch basierte Software kann der Congree Authoring Server genannt werden, der seine Sprachprüfung mit einer Terminologiekomponente und der Möglichkeit zur Satzwiederverwendung kombiniert.
Auf diese Weise können Anforderungen softwaregestützt optimiert werden, was sämtlichen Problemen entgegenwirkt, die durch sprachlich schlechte Anforderungsdokumente verursacht werden. Es entsteht ein Vorteil für alle Stakeholder des Prozesses.